豆瓣爬虫实例
本文提供 3 个例子来说明如何利用 Python 爬取豆瓣的数据。
用 requests 获取页面
三个实例都要用到 request 库来获取页面资源。
1 | def getHTMLText(url): # 获取网页的HTML源码 |
实例一:豆瓣国产电视剧爬虫
观察所需爬取的页面
所需爬取的页面为按时间排序的国产电视剧评分等信息。
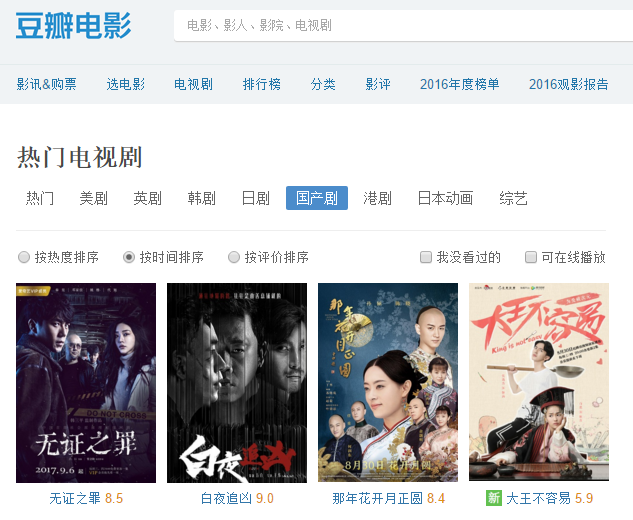
查看其源代码发现电视剧列表内容是由 js 加载的。

获取电视剧豆瓣地址列表
打开控制台,观察一下 network 中往返的数据。
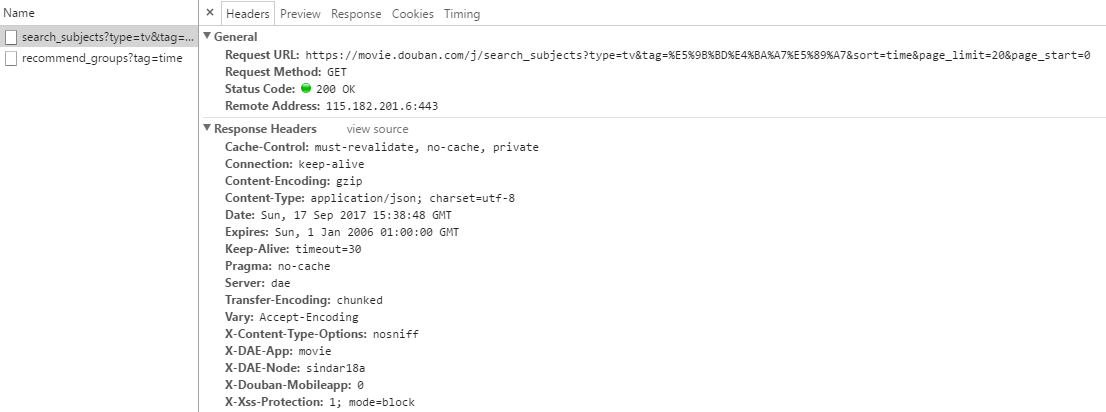
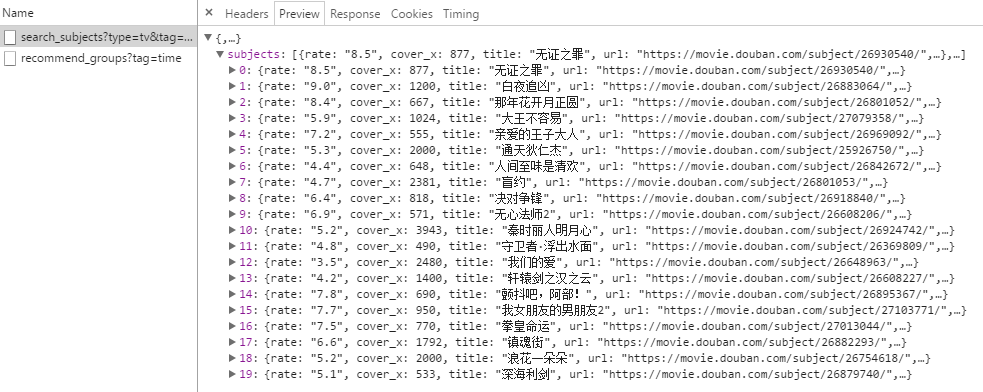
观察到网页通过查询 https://movie.douban.com/j/search_subjects?type=tv&tag=国产剧&sort=time&page_limit=20&page_start=0
其中 type 是分类(movie,tv);tag 是小分类(热门,美剧,英剧,韩剧,日剧,国产剧,港剧,日本动画,综艺);sort 是排序(recommend,time,rank);page_limit 是每页展示的电视剧数量(不可修改);page_start 是起始页面,为 20 的倍数(例如,第一页是 0,第二页是 20 等等)。
返回的是 json 数据,直接读取其 url 字段即可。
1 | def getTVdramalist(url, Numofpage): |
分析电视剧详情页
对于上面获取的每一个 url 对应一个电视剧详情页。

查看其源代码发现电视剧详情内容是由 HTML 加载的。

则用 beautifulsoup 库结合正则表达式 re 库分析并获取所需字段。
1 | def getTVdramainfo(url, writer): |
从property为v:itemreviewed的标签可以得到电视剧名。
从property为v:average的标签可以得到评分。
从property为v:votes的标签可以得到评分人数。
<span class="pl">集数:</span> 12<br/> 和 <span class="pl">单集片长:</span> 55分钟<br/> 的标签属性和其他标签的属性都一样,这里直接用正则表达式进行查找反而更方便。
存储所爬信息到数据库
这里使用 sqlite3 库实现
1 | def dbtablecreate(): |
可以用SQLiteSpy.exe查看数据库。

实例二:豆瓣正在上映电影爬虫
观察所需爬取的页面
所需爬取的页面为正在上映电影。
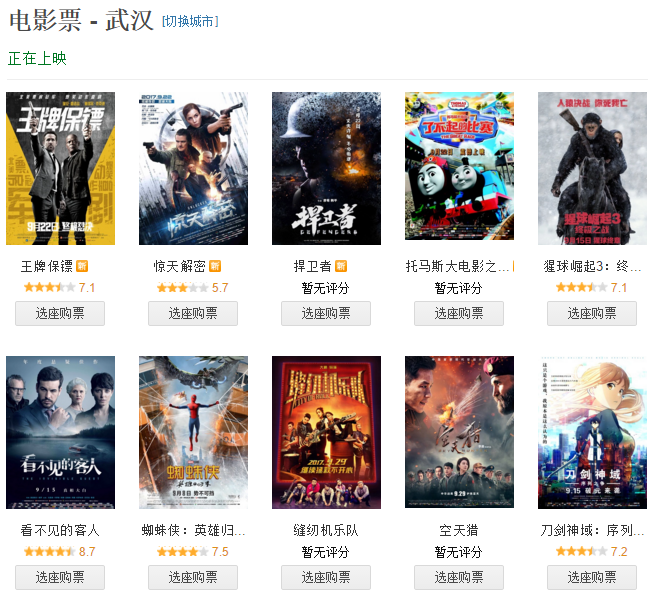
查看其源代码。

获取电影信息
1 | def getnowshowing(url, city): |
从源码发现电影列表内容分为正在上映和即将上映两块,soup.find(class_="lists") 只返回第一个符合条件的标签。
其每一个孩子节点包含每一个电影信息。所有信息都存在孩子节点的 <li> 标签内,所以只取 Tag 对象,Tag 对象的属性访问与字典一样。
注意 data-duration 的值有可能为空,所以要单独判断。
eachmoive ['data-duration'] 返回 'xxx 分钟 ' 的 Unicode 对象,.encode('utf-8') 将 Unicode 对象转换成 string 对象。filter(str.isdigit, str) 提取 str 中数字。
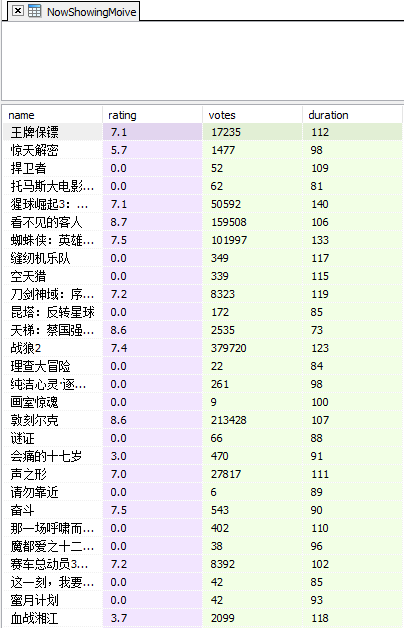
存储所爬信息到数据库
这里使用 sqlite3 库实现
1 | def dbtablecreate(): |
可以用SQLiteSpy.exe查看数据库。
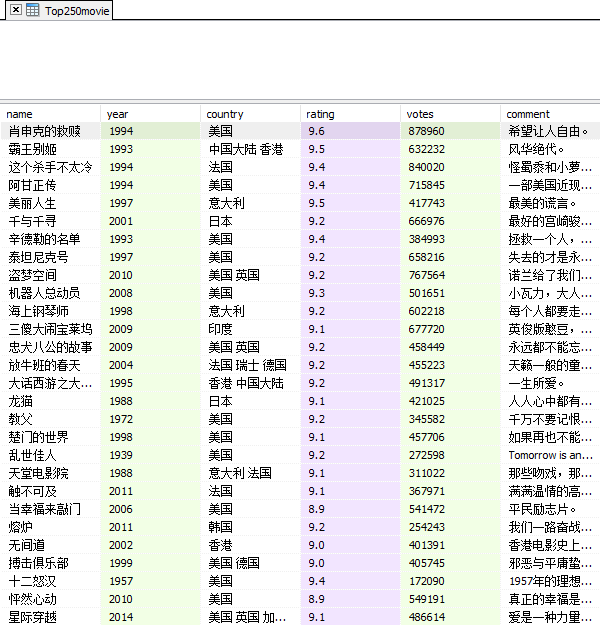
实例三:豆瓣电影 TOP250 爬虫
观察所需爬取的页面
所需爬取的页面为豆瓣电影 Top250。
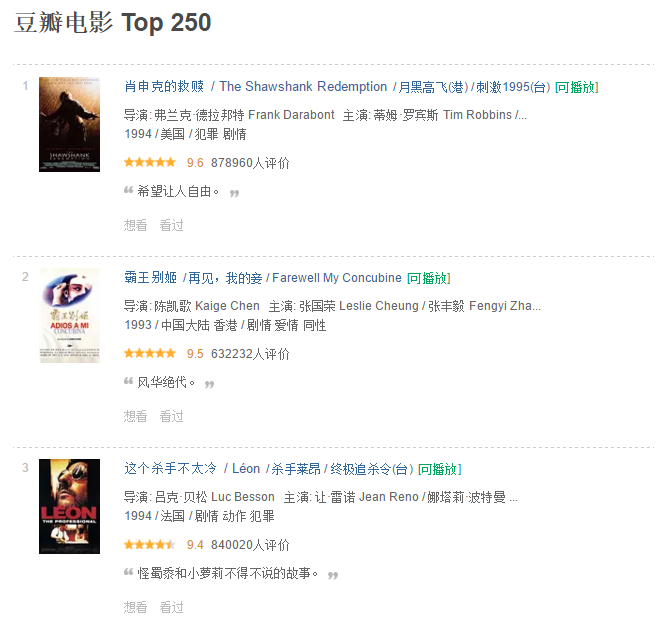
查看其源代码。

获取电影信息
1 | def getTop250moive(url, Numofpage): |
从网址发现,Top250 的电影分别展示在 10 个页面,每个页面展示 25 条电影信息,所以 url 的 start 参数为 25 的倍数,值为 0-9。
从源码发现 soup.find(class_="info") 返回每一个电影的信息所在的标签如图。
从样式为 title 的标签可以得到电影名。
从第一个 p 标签可以返回导演、主演、上映年份、国家、类型等信息,并且是分列 2 行,
用.split('\n')[2] 得到第 2 行的字符串,.strip()[0:4]) 去掉空格并取前 4 个字符作为年份。
.split('/')[1].strip() 以斜线分隔符分割字符串并取出第二段字符串并去掉前后空格,即国家信息。
从 property 为 v:average 的标签可以得到评分。
由于评分人数从 <span>878960人评价</span> 标签中获取,但是 span 标签没有任何属性。
所以有两种方法:
1. 通过 find(property="v:best") 找到上一个平行节点,然后通过.next_sibling.next_sibling.string 访问。
2. 通过 eachmoive.find(text=re.compile(u"人评价")) 直接用正则表达式查找相应的字符串。
最后通过 filter(str.isdigit, str) 提取 str 中数字。
从样式为 inq 的标签可以得到电影评论,注意电影可能没有评论,所以要单独判断。
存储所爬信息到数据库
这里使用 sqlite3 库实现
1 | def dbtablecreate(): |
可以用SQLiteSpy.exe查看数据库。