Python 爬虫
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
本文介绍基本的网络爬虫的方法,并给出一个具体实例。
Reference:公开课
爬虫许可
大部分网站都会在其网站根网址上发布 robots 协议
如豆瓣网:https://www.douban.com/robots.txt
1 | User-agent: * |
Requests 库
Reference:Python 网络爬虫与信息提取 (一):网络爬虫之规则
安装:pip install requests。
Requests 库的主要方法
| 方法 | 说明 |
|---|---|
requests.request() |
构造一个请求,支撑以下各方法的基础方法 |
requests.get() |
获取 HTML 网页的主要方法,对应于 HTTP 的 GET,请求获取 url 位置的资源 |
requests.head() |
获取 HTML 网页头信息的方法,对应于 HTTP 的 HEAD,请求获取 url 位置资源的响应消息报告,获得该资源的头部信息 |
requests.post() |
向 HTML 网页提交 post 请求的方法,对应于 HTTP 的 POST,请求向 url 位置的资源后附加新的数据 |
requests.put() |
向 HTML 网页提交 put 请求的方法,对应于 HTTP 的 PUT,请求向 url 位置存储一个资源,覆盖原 url 位置的资源 |
requests.patch() |
向 HTML 网页提交局部修改请求的方法,对应于 HTTP 的 PATCH,请求局部更新 url 位置的资源,即改变该处资源的部分内容 |
requests.delete() |
向 HTML 网页提交删除请求的方法,对应于 HTTP 的 DELETE,请求删除 url 位置存储的资源 |
get 方法
在爬虫中主要使用 get 方法,其他方法参数与 get 方法类似。
r = requests.get(url): 右边构造一个向服务器请求资源的 Requests 对象,左边返回一个包含服务器资源的 Response 对象给 r。
完整参数:requests.get(url,params=None,**kwargs), 实则由 request 方法封装。
Resonse 对象的五个属性:
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP 请求的返回状态,200 表示连接成功,404 表示失败 |
| r.text | HTTP 响应内容的字符串形式,即 url 对应的页面内容 |
| r.encoding | HTTP header 中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP 响应内容的二进制形式 |
异常处理
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如 DNS 查询失败、拒绝连接等 |
| requests.HTTPError | HTTP 错误异常 |
| requests.URLRequired | url 缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求 url 超时,产生超时异常 |
使用 r.raise_for_status () 方法构建通用代码框架:
1 | def getHTMLText(url) |
Requests 库主要方法
requests.request(method,url,**kwargs)
- method (请求方式) 包括:GET/HEAD/POST/PUT/PATCH/DELETE/OPTIONS。
- **kwargs (控制访问参数) 包括:params (添加键值到 url 后)/data (字典 / 字节序列等作为 Request 的内容)/json/headers (HTTP 定制头)/cookies (Request 中的 cookie)/auth (元祖,支持 HTTP 认证)/files (传输文件)/timeout/proxies (设定访问代理服务器)/allow_redirects (重定向开关)/stream (获取内容立即下载开关)/verify (认证 SSL 证书开关)/cert (本地 SSL 证书路径)。
Beautiful Soup 库
Beautiful Soup 库可对 HTML/XML 格式进行解析并提取相关信息。
Beautiful Soup 库是解析 / 遍历 / 维护 "标签" 的功能库,引用方式:from bs4 import BeautifulSoup。
Reference:Python 网络爬虫与信息提取 (二):网络爬虫之提取
安装:pip install beautifulsoup4。
Beautiful Soup 库的解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| HTML 解析器 | BeautifulSoup(mk,'html.parser') |
安装 bs4 库 |
| lxml 的 HTML 解析器 | BeautifulSoup(mk,'lxml') |
pip install lxml |
| lxml 的 XML 解析器 | BeautifulSoup(mk,'xml') |
pip install lxml |
| html5lib 的解析器 | BeautifulSoup(mk,'html5lib') |
pip install html5lib |
Beautiful Soup 类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用 <> 和 </> 标明开头和结尾 |
| Name | 标签的名字,<p>...</p> 的名字是 'p',格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs 或者 <tag>['attrs'] |
| NavigableString | 标签内非属性字符串,<>...</> 中的字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的 Comment 类型 |
- 任何存在于 HTML 语法中的标签都可用
soup.<tag>访问获得,存在多个取第一个。 - 每个
<tag>有自己的名字,通过<tag>.name获取,字符串类型。 - 每个
<tag>有 0 或多个属性,字典类型。 - 每个
<tag>内有字符串,可以跨越多个标签层次,如果字符串不是注释,则 NavigableString 类型。 - 如果
<tag>内的字符串是注释,则返回 Comment 类型。
HTML 内容遍历方法
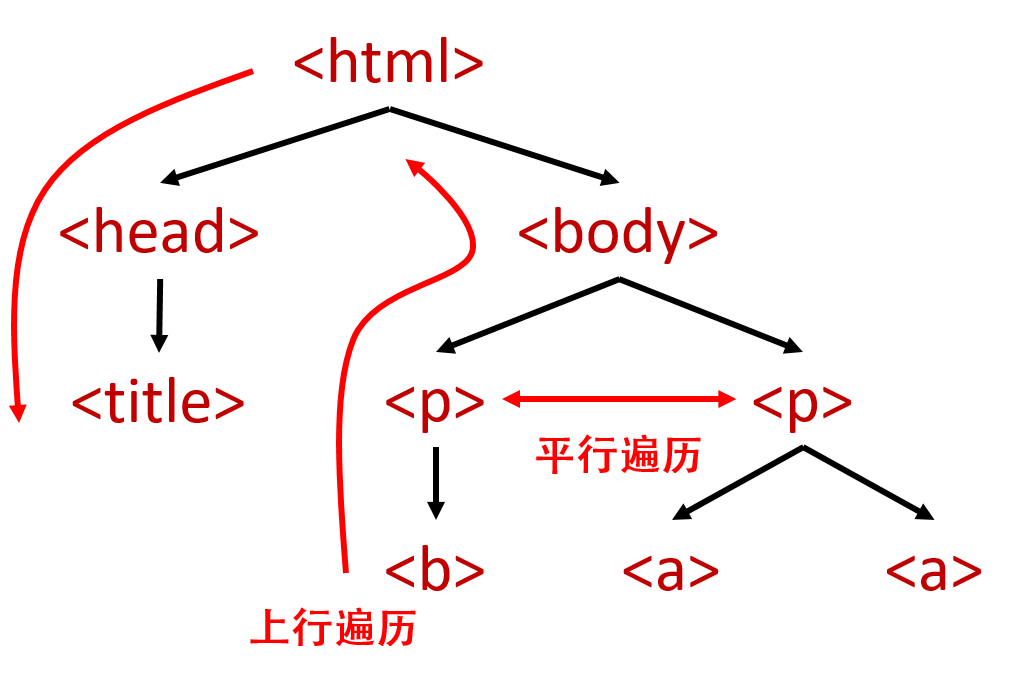
| 属性 | 说明 | 遍历方式 |
|---|
<tag> 所有儿子节点存入列表
下行遍历
.children |子节点的迭代类型,与.contents类似,用于循环遍历儿子节点.descendants |子孙节点的迭代类型,用于循环遍历子孙节点
.parent |节点的父标签 上行遍历 .parents |节点先辈标签的迭代类型,用于循环遍历先辈节点
.next_sibling |返回按照HTML文本顺序的下一个平行节点标签 平行遍历
.previous_sibling | 返回按照 HTML 文本顺序的上一个平行节点标签
.next_siblings | 迭代类型,返回按照 HTML 文本顺序的后续所有平行节点标签
.previous_siblings | 迭代类型,返回按照 HTML 文本顺序的前续所有平行节点标签
1 | for child in soup.body.children: |
HTML 格式输出
使用 prettify() 方法,为 HTML 文本 <> 及其内容增加 '' 并且可用于标签 / 方法。
HTML 内容查找方法
<>.find_all(name,attrs,recursive,text='',**kwargs)
返回一个列表类型,存储查找的结果
name: 对标签名称的检索字符串
attrs: 对标签属性值的检索字符串,可标注属性检索,如果 attrs 是 class,则替换为 class_。
recursive: 是否对子孙全部搜索,默认 True
text='': 对字符串域进行检索,其中可以用 re.compile () 来进行正则表达式检索
由.find_all() 扩展的七个方法:
| 方法 | 说明 |
|---|---|
<>.find() |
搜索且只返回一个结果,同.find_a11() 参数 |
<>.find_parents() |
在先辈节点中搜索,返回列表类型,同.find_all() 参数 |
<>.find_parent() |
在先辈节点中返回一个结果,同.find() 参数 |
<>.find_next_siblings() |
在后续平行节点中搜索,返回列表类型,同.find_a11() 参数 |
<>.find_next_sibling() |
在后续平行节点中返回一个结果,同.find() 参数 |
<>.find_previous_siblings() |
在前续平行节点中搜索,返回列表类型,同.find_a11() 参数 |
<>.find_previous_sibling() |
在前续平行节点中返回一个结果,同.find() 参数 |
信息组织与提取方法
信息标记的三种形式及比较:
XML (Extensible Markup Language) 是最早的通用信息标记语言,可扩展性好,但繁琐;标签由名字和属性构成,形式有:
1 | <name>...</name> |
JSON(JavaScript Objection Notation)适合程序处理,较XML简洁;有类型的键值对,形式有:
1 | "key":"value" |
YAML(YAML Ain't Markup Language)文本信息比例最高,可读性好;无类型的键值对,形式有:
1 | key:value |
Re (正则表达式) 库
regular expression = regex = RE
是一种通用的字符串表达框架,用来简洁表达一组字符串的表达式,也可用来判断某字符串的特征归属。
Reference:Python 网络爬虫与信息提取 (三):网络爬虫之实战 ;Python 正则表达式指南
正则表达式的语法
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
\cx |
匹配由 x 指明的控制字符。例如,\cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
\d |
匹配任何数字。等价于 [0-9]。 |
\D |
匹配任何非数字。等价于 [^\d]。 |
\w |
匹配任何单词字符。等价于 [a-zA-Z0-9_]。 |
\W |
匹配任何非单词字符。等价于 [^\w]。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [^\f\n\r\t\v]。 |
\t |
匹配一个制表符。等价于 \x09 和 \cI。 |
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
所谓特殊字符,就是一些有特殊含义的字符。
若要匹配这些特殊字符,必须首先使字符 "转义",即,将反斜杠字符。下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
^ |
匹配输入字符串的开始位置,在多行模式中匹配每一行的结尾。 除非在方括号表达式中使用,此时它表示不接受该字符集合。 |
$ |
匹配输入字符串的结尾位置,在多行模式中匹配每一行的结尾。 |
(...) |
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。从表达式左边开始每遇到一个分组,则编号 + 1。分组表达式作为一个整体可以后接数量词。表达式中的 | 仅在分组中有效。 |
(?P<name>...) |
分组,除了原有编号外再指定额外别名。 |
\<number>(<?P=name) |
引用编号为 number 或者别名为 name 的分组。 |
[...] |
字符集,对应的位置可以是字符集中任意字符。 字符集中的字符可以逐个列出,也可以给出范围,如 [abc] 或 [a-c]。第一个字符如果是 ^ 则表示取反,如 [^abc] 表示不是 a 或 b 或 c 的其他字符。所有的特殊字符在字符集中都失去其原有的特殊含义。在字符集中如果要使用 ] 或 - 或 ^,可以在前面加上反斜杠,或者把] 或 - 放在第一位,把 ^ 放在非第一位。 |
{n} |
n 是一个非负整数。匹配确定的 n 次。 |
{n,} |
n 是一个非负整数。至少匹配 n 次。{1,} 等价于 +。{0,} 则等价于 *。 |
{n,m} |
m 和 n 均为非负整数,其中 n<=m。最少匹配 n 次且最多匹配 m 次。{0,1} 等价于 ?。请注意在逗号和两个数之间不能有空格。 |
* |
匹配前面的子表达式零次或多次。 |
+ |
匹配前面的子表达式一次或多次。 |
. |
匹配除换行符 \n 之外的任何单字符。在 DOTALL 模式中也能匹配换行符。 |
? |
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。 |
| |
左右表达式任意一个。 |
经典实例
| 正则表达式 | 匹配字符串 |
|---|---|
^[A-Za-z]+$ |
由 26 个字母组成的字符串 |
^[A-Za-z0-9]+$ |
由 26 个字母和数字组成的字符串 |
^-?\d+$ |
整数形式的字符串 |
^[1-9][0-9]*$ |
正整数形式的字符串 |
[\u4e00-\u9fa5] |
匹配中文字符 |
正则表达式相关注解
- 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python 里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。实际我们一般使用非贪婪模式来提取。 - 反斜杠问题
与大多数编程语言相同,正则表达式里使用\作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符\,那么使用编程语言表示的正则表达式里将需要 4 个反斜杠\\\\:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python 里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r'\\'表示。同样,匹配一个数字的\\d可以写成r'\d'。使用原生字符串,就不用担心漏写了反斜杠,写出来的表达式也更直观。
Re 库的基本使用
正则表达式的表示类型为 raw string 类型 (原生字符串类型), 表示为 r'text'。
Re 库主要功能函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回 match 对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回 match 对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是 match 对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
search 方法
re.search(pattern, string, flags = 0)
参数 flag 是匹配模式,取值可以使用按位或运算符’|’表示同时生效。
其他方法的参数与 search 类似。sub 方法多一个参数 repl,re.sub(pattern, repl, string, flags = 0)。
| flag | 说明 |
|---|---|
| re.I(IGNORECASE) | 忽略大小写 |
| re.M(MULTILINE) | 多行模式,改变 '^' 和 '$' 的行为 |
| re.S(DOTALL) | 点任意匹配模式,改变 '.' 的行为 |
| re.L(LOCALE) | 使预定字符类 |
| re.U(UNICODE) | 使预定字符类 |
| re.X(VERBOSE) | 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。 |
Match 对象
一次匹配的结果,包含了很多关于此次匹配的信息,可以使用 Match 提供的可读属性或方法来获取这些信息。
属性
| 属性 | 说明 |
|---|---|
| string | 匹配时使用的文本。 |
| re | 匹配时使用的 Pattern 对象。 |
| pos | 文本中正则表达式开始搜索的索引。值与 Pattern.match () 和 Pattern.seach () 方法的同名参数相同。 |
| endpos | 文本中正则表达式结束搜索的索引。值与 Pattern.match () 和 Pattern.seach () 方法的同名参数相同。 |
| lastindex | 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为 None。 |
| lastgroup | 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为 None。 |
方法
| 方法 | 说明 |
|---|---|
group([group1, …]) |
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。可以使用编号也可以使用别名。 编号 0 代表整个匹配的子串,不填写参数时,返回 group(0),没有截获字符串的组返回 None,截获了多次的组返回最后一次截获的子串。 |
groups([default]) |
以元组形式返回全部分组截获的字符串。相当于调用 group(1,2,…last)。default 表示没有截获字符串的组以这个值替代,默认为 None。 |
groupdict([default]) |
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default 含义同上。 |
start([group]) |
返回指定的组截获的子串在 string 中的起始索引(子串第一个字符的索引)。group 默认值为 0。 |
end([group]) |
返回指定的组截获的子串在 string 中的结束索引(子串最后一个字符的索引 + 1)。group 默认值为 0。 |
span([group]) |
返回 (start(group), end(group))。 |
expand(template) |
将匹配到的分组代入 template 中然后返回。template 中可以使用 \id 或 \g<id> 或 \g<name> 引用分组,但不能使用编号 0。\id 与 \g<id> 是等价的,但 \10 将被认为是第 10 个分组,如果你想表达 \1 之后是字符'0',只能使用 \g<1>0。 |
Pattern 对象
Pattern 对象是一个编译好的正则表达式,通过 Pattern 提供的一系列方法可以对文本进行匹配查找。
Pattern 不能直接实例化,必须使用 re.compile () 进行构造。
Pattern 提供了几个可读属性用于获取表达式的相关信息:
| 属性 | 说明 |
|---|---|
| pattern | 编译时用的表达式字符串。 |
| flags | 编译时用的匹配模式。数字形式。 |
| groups | 表达式中分组的数量。 |
| groupindex | 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。 |
所以 re.xxx(pattern, string, flags = 0) 可以写做 pattern.xxx(string, flag)。
SQLite 库
SQLite 简介
- 轻量级
- 速度快
- 无需部署
- 没有服务器
- 很少或不需要进行管理
- 由于 SQLite 数据库的驱动已经在 Python 里面了,可以直接使用
import sqlite3
创建数据库
conn = sqlite3.connect("数据库名称.db")
如果数据库不存在,那么它就会被创建,最后将返回一个数据库对象。
创建游标对象
cur = conn.cursor()
创建数据库表
1 | try: |
这里 ' 键 i' 为键的名称,其中键 1 为主键,键类型有 TEXT(文本字符串,使用数据库编码 UTF-8、UTF-16BE 或 UTF-16LE 存储),REAL(浮点值,存储为 8 字节的 IEEE 浮点数字),INT(带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中),NULL(空值)。
INSERT 操作
单个插入
1 | try: |
批量插入
1 | try: |
UPDATE 操作
1 | try: |
SELECT 操作
1 | try: |
DELETE 操作
1 | try: |
关闭数据库
1 | cursor.close() # 关闭Cursor |
将数据库中的数据导出为 csv 文件:
1 | conn = sqlite3.connect('文件名.db') |